はじめに
深層学習は大規模言語モデルや画像認識など, 多くの応用において飛躍的な性能を上げている.
しかしながら, 深層学習の原理には謎が多い.
謎の例として, DNNは訓練データ数よりパラメータ数の方が多い(over parametrization)モデルでありながら, 汎化性能が高いという現象がある. これは従来の統計的学習理論で考えられていた bias-variance tradeoff の法則に反する. この現象はdouble descent として知られている.
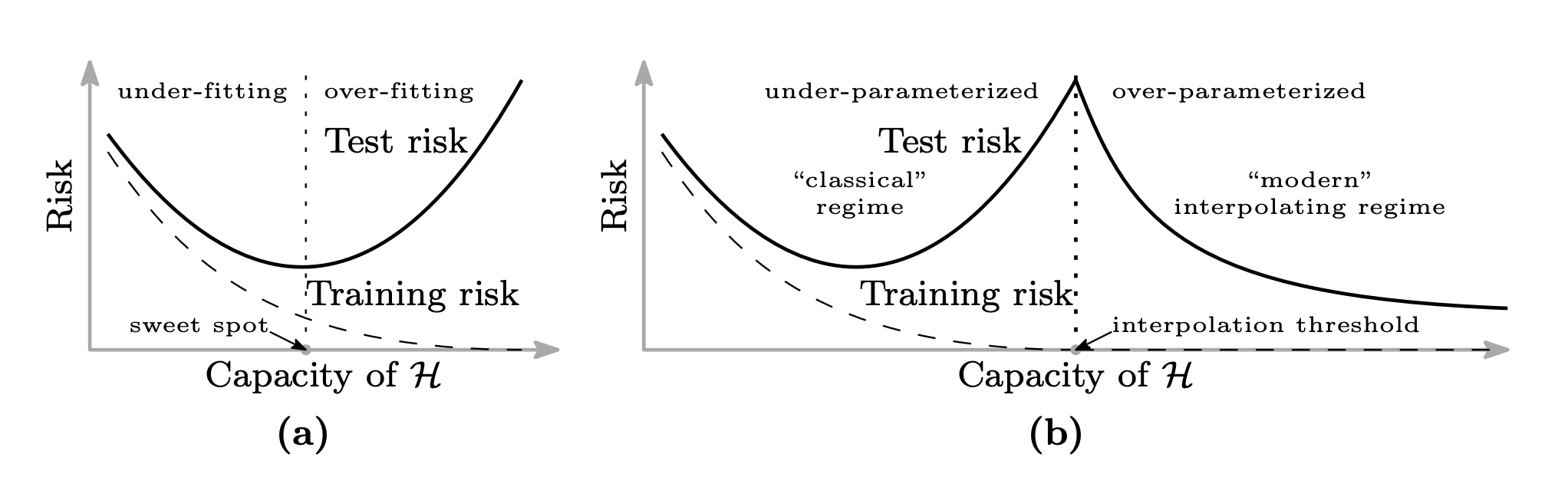 Figure: Belkin et al. "Reconciling modern machine learning practice and the bias-variance trade-off", 2018
Figure: Belkin et al. "Reconciling modern machine learning practice and the bias-variance trade-off", 2018
他の例として, 深層学習の学習がなぜうまくいくかという謎がある. 通常, DNNモデルのような関数の最適化は非凸最適化問題であり, 最適解を見つけることは難しい. しかし, 現実的には非常に良い解が得られる.
このような謎を解明すべく, 深層学習理論(theory of deep learning)が研究されている.
深層学習理論はいくつかの分野がある.
- 表現能力: DNNモデルの表現能力
- 汎化能力: 未知データに対する汎化性能
- 最適化能力: 最適化がうまく理由
- etc
表現能力については, 普遍性定理(Universal approximation theorem) 等の有用な定理が示されてきた. その一方で, 汎化能力や最適化能力についての理解はまだまだである.
これらについて学習中のダイナミクス(Learning Dynamics)を解析することで理解を深めようとする研究が盛んに行われている.
本稿では, 学習中のダイナミクスに着目した研究の礎となっている Neural Tangent Kernel (NTK) 理論を紹介する. 構成については”Some Math behind Neural Tangent Kernel” を大いに参考にした.
NOTE: NTK理論は, 深層学習理論の研究を超えて, “Editing Models with Task Arithmetic”等のモデルパラメータの算術における説明に使われるなど[Ortiz-Jimenez et al. 2023], 深層学習研究における基本ツールとなりつつあります.
Table of contents
Open Table of contents
θ,f(x;θ) のダイナミクスとNeural Tangent Kernel (NTK) の定義
学習中のダイナミクスにおいて重要なものが, モデルのパラメータθ∈RP, 出力f(x;θ)∈F:R×RP→Rである. 簡単のためモデルの入出力の次元はそれぞれ1次元とした. θ,f(x;θ) はエポックをtとした時, tによって時間発展する.
ここでは, θ,f(x;θ) が学習中に従う微分方程式を導出する.
訓練データD={(xi,yi)}i=1Nが与えられるとする. この時, 損失は以下のように定義される.
L(θ):=N1i∑Nl(f(xi;θ),yi)
ここで, 以下のような微分の連鎖律を適用すると,
dθidl(f(x;θ))=dfdldθidf
以下のように損失L(θ)の勾配が計算できる. ただし∇θL(θ):=(∂θ1∂L,…,∂θP∂L), Pはパラメータの総数とする.
∇θL(θ)=N1i∑N∇θf(xi;θ)dfdl(f,yi)
続いて, パラメータの時間微分を考える.
通常, 勾配降下法は, 以下のようにパラメータが更新される. ただし本稿では全体を通してFull Batch Gradient Descentとする.
θt+1=θt−η∇θL(θ)
更新の幅を小さくした時, 以下のようにパラメータに関する微分方程式が得られる(Gradient Flow).
dtdθ=−η∇θL(θ)=−ηN1i∑N∇θf(xi;θ)dfdl(f,yi)
さらに, これを用いてf(x;θ) に関する微分方程式が得られる.
dtdf(x;θ)=i∑dθidf(x;θ)dtdθi=∇θf(x;θ)(−η∇θL(θ)⊤)=−Nηi∑N∇θf(x;θ)∇θf(xi;θ)⊤dfdl(f,yi)=−Nηi∑NK(x,xi;θ)dfdl(f,yi)
ただし,
K(x,x′;θ):=∇θf(x;θ)∇θf(x′;θ)⊤
このK(x,x′;θ) をNeural Tangent Kernel (NTK) と呼ぶ.
なお, NTKは以下のように計算される.
K(x,x′;θ)=p∑P∂θp∂f(x;θ)∂θp∂f(x′;θ)
この時, NTKは
- K:R×R×RP→Rという写像であり,
- K(x,x′;θ)=K(x′,x;θ)
である.
このように, NTKはモデルの出力f(x;θ)の時間発展を左右する重要なfactorであり, 深層学習理論において学習中のダイナミクスを解析するのに用いられている.
次節以降のため, 以下のように定義しておく.
f(X;θ):=(f(x1;θ),…,f(xn;θ))⊤
K(x,X;θ):=∇θf(x;θ)∇θf(X;θ)⊤
なお, 出力のサイズは, (1 _ P)_(P _ N) = (1 _ N)
K(X,X):=∇θf(X;θ)∇θf(X;θ)⊤
なお, 出力のサイズは, (N _ P) _ (P _ N) = (N _ N)
無限の幅のDNNのNTKは学習中ずっとconstant
ここでは, NTKに関する驚きの定理を紹介する.
[Jacot et al. 2018] は, いくつかの仮定(ntk parametrization, activation function, learning rate等の制約)のもとで以下の定理が成り立つことを示した.
Fully-ConnectedなDNNの中間層の幅を無限とした時(各層lの重みの次元数をnlとした時, n1,…,nL−1→∞), 各層の出力fl(x;θ)で定義されるNTK K∞l(x,x′;θ)は重みθ に依存しない. すなわちK∞l(x,x′)と表すことができ, 入力x,x′と, 層の深さ, activation function, パラメータの初期化の分散のみから定まる.
なんとも驚きの結果である. 驚きを感じるために, K(x,x′;θ) の定義をもう一度振り返ってみよう.
K(x,x′;θ):=∇θf(x;θ)∇θf(x′;θ)⊤
x,x’ を入力としたときのモデルの出力のパラメータに関する勾配の内積で定義されており, この値は, 通常, 学習中変化するパラメータの値に依存する.
しかし, 各層の幅を無限とした時(n1,…,nL→∞), K∞(x,x′;θ)はパラメータθによらず一定となる.
すなわち, 各層の幅が無限なモデルは, 初期化時K0(x,x′)からすでに重みに依存せず値が定まり, 学習中に重みが変化してもNTKの値は変わらず一定である. さらに言い換えれば, モデルの学習中, NTKは不変量となる.
不変量は古来より複雑な対象物を解析する際に重宝されてきた. 例えば物理学では時間tに一定なエネルギーに着目し様々な定理を導いてきた.
幅が無限という理想的な状況で不変量となるNTKが, 深層学習理論において重要な理由が垣間見える.
学習中のf(x;θ) のダイナミクスについて
前章の定理から何が言えるだろうか. f(x;θ) が従う微分方程式を見てみよう.
dtdf(x;θ)=−Nηi∑NK(x,xi;θ)dfdl(f,yi)
幅を無限にした時, K(x,xi;θ)=K∞L(x,xi)より以下のようになる.
dtdf(x;θ)=−Nηi∑NK∞L(x,xi)dfdl(f,yi)
x, X, Yは学習中定数であり, NTKはこの時定数であり, 右辺が簡単になった.
さらに, 損失関数がMSE, すなわち L(θ)=2N1∥∥f(X;θ)−Y∥∥2の時, ∇fL(θ)=N1(f(X;θ)−Y)より
dtdf(x;θ)=−ηK∞(x,X)(f(X;θ)−Y)
と簡略化できる. さらに, g(X;θ):=f(X;θ)−Y とすると, X,Y は定数より
dtdg(X;θ)=−ηK∞(X,X)g(θ)
これは典型的な解ける形の常微分方程式であり以下のように解ける. ただしC は定数.
g(X;θ)=exp(−ηK∞(X,X)t)C
よって
f(X;θ)=exp(−ηK∞(X,X)t)C+Y
また, t=0の時, C=f(θ(0))−Y より
f(X;θ(t))=exp(−ηK∞(X,X)t)(f(X;θ(0))−Y)+Y
任意の入力xについても以下のように陽に解ける.
f(x;θ(t))=f(x;θ(0))+K∞(x,X)K∞(X,X)−1(I−exp(−ηK∞(X,X)t))(Y−f(X;θ(0))
実際にtで微分すると
dtdf(x;θ(t))=−ηK∞(x,X)exp(−ηK∞(X,X)t)(f(X;θ(0))−Y)
この式に, f(X;θ(0))−Y=exp(−ηK∞(X,X)t)−1(f(X;θ(t))−Y)を代入して, 整理すると
dtdf(x;θ(t))=−ηK∞(x,X)(f(X;θ(t))−Y)
よって元の微分方程式が得られた.
以上のように, 時刻tにおける出力f(x;θ) が解析的に得られた.
この結果, f(x;θ(t)) は, Gradient Descentをせずとも, K∞=K0とf(θ(0)) を計算することで計算できる.
NTKが不変量, 損失がMSEという仮定から非常に面白い結果が生まれた.
無限の幅のDNNは学習中パラメータに関して線形モデル
話を変えて, 時刻tにおけるモデルf(x;θ(t)) をdθ:=θ(t)−θ(0)が小さい時, パラメータθ に関して, 初期値θ(0) 周りでテイラー展開をして1次近似できるものとしてみよう.
flin(x;θ(t))≈f(x;θ(0))+∇θf(x;θ(0))(θ(t)−θ(0))⊤
この時, f(θ(t)) はθ(t) に関して線形である.
このように近似した時, tが小さければGradient Descentの更新式から
θ(t)−θ(0)=−η∇θL(θ(0))=−ηN1i∑N∇θf(xi;θ(0))dfl(f,yi)
であり, flin(x;θ(t))に代入すると,
flin(x;θ(t))−f(x;θ(0))=∇θf(x;θ(0))(−ηN1i∑N∇θf(xi;θ(0))dfl(f,yi))⊤
tを小さくして整理すると,
dtdflin(θ(t))=−ηN1i∑N∇θf(x;θ(0))∇θf(xi;θ(0))⊤dfl(f,yi)=−ηN1i∑NK(x,xi;θ(0))∇fl(f,yi)
以上から, flin(θ(t)) の従う微分方程式のNTKはK(θ(0)) で一定になる.
この方程式は, 前章で導出した, 幅を無限にした時の微分方程式
dtdf(x;θ)=−Nηi∑NK∞L(x,xi)∇fl(f,yi)
と一致している.
[Lee et al. 2019] は幅が無限の時, 学習中のf(θ(t))は初期パラメータ周りで一次近似した線形モデルとして表されることを示した. この結果は, パラメータの探索が初期値まわりにとどまることも意味しており, DNNモデルの自由度を暗黙的に制約する暗黙的正則化との繋がりが示唆される.
数値実験
ここでは, NTKの理論が有限幅において, どの程度成り立つか実験する.
本実装は以下のリポジトリから再現できる.
実装はJAXを用いた. JAXはヤコビアンを計算する関数としてjax.jacfwd(), jax.jacrev() の二つが用意されている. どちらも同じ計算結果になるが, 内部の実装が異なっており, jacfwd() はTallな行列, jacrev() はWideな行列に効果的である[JAX doc]. 今回のヤコビアンは出力の次元数よりパラメータの次元数の方が大きいWideな行列であるため, jacrev() が適している.
ただし今回は出力がスカラーであるため, jax.grad()でよい.
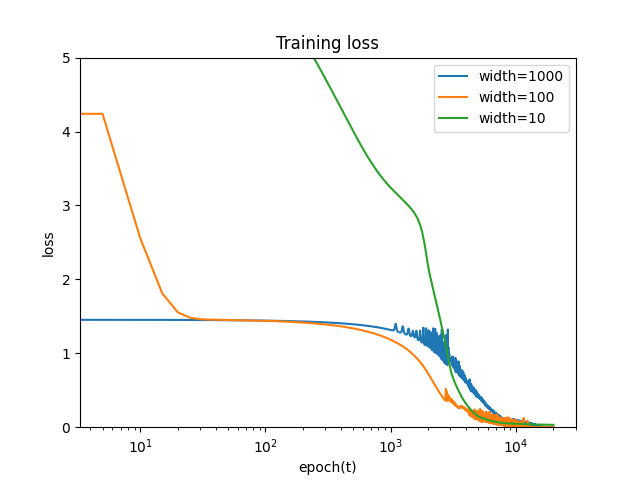
設定としては, 中間層の数depth=5, 各層の幅width={10,100,1000}, 入力, 出力を1次元, learning rate η= 0.001, epoch数を20000とする. バッチ数については, NTK理論はFull Batchを仮定していたが, 現実的にはMini Batchを使うことが多いため, Batch数を1, 5, 10と変えて実験した.
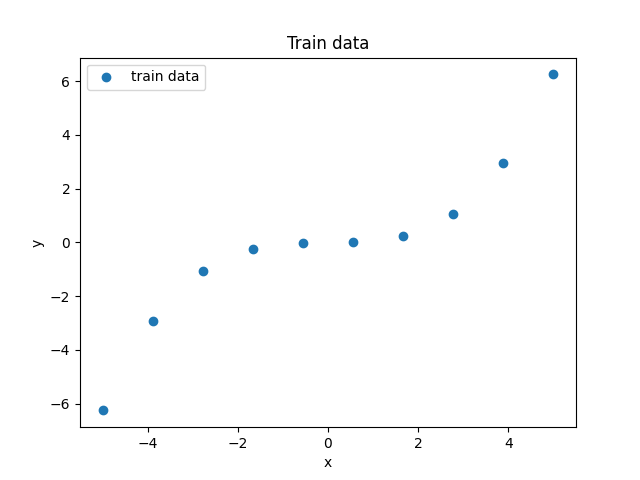
訓練データは簡単のため以下のようなN=10の点とする.
本実験では, 学習中のダイナミクスを測る指標として以下の3つを用いる.
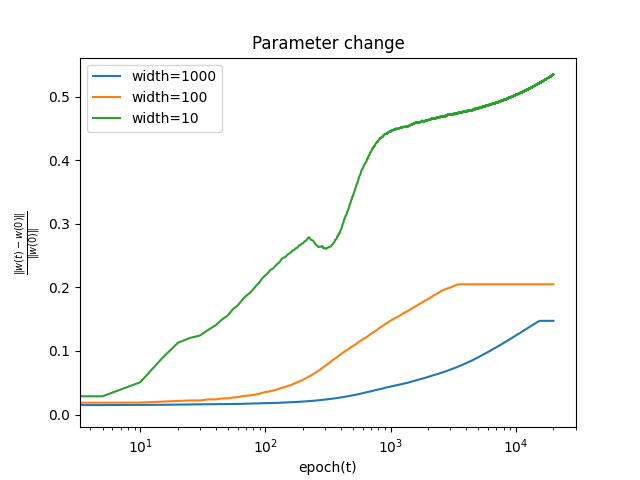
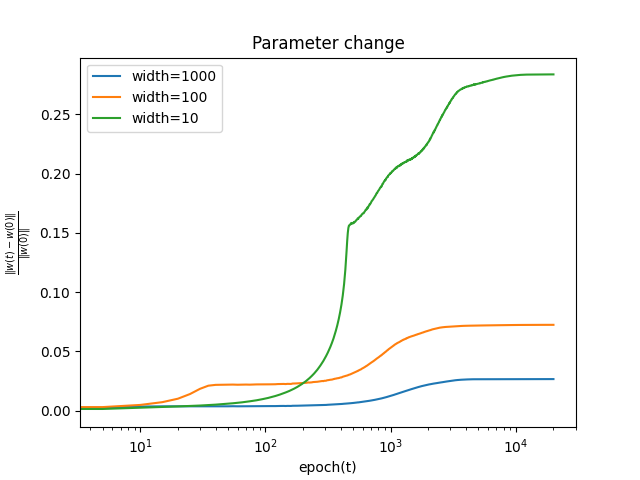
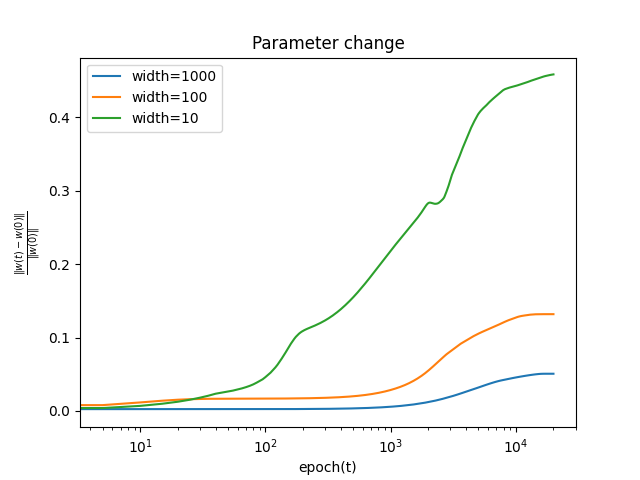
学習中にパラメータが初期値からどの程度変化するか, 以下の式を用いて測る.
∣∣θ(0)∣∣2∣∣θ(t)−θ(0)∣∣2
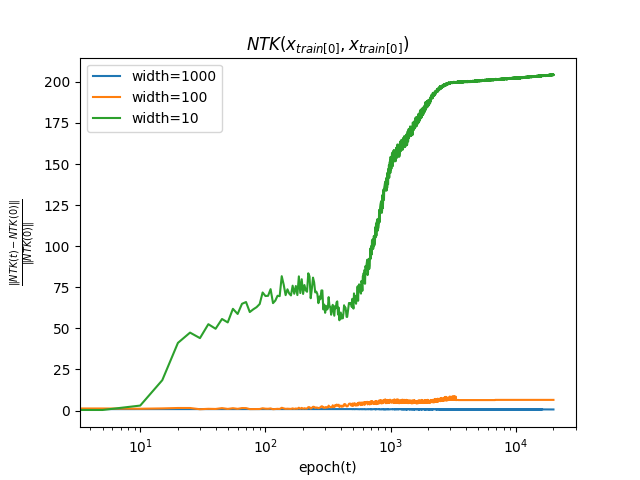
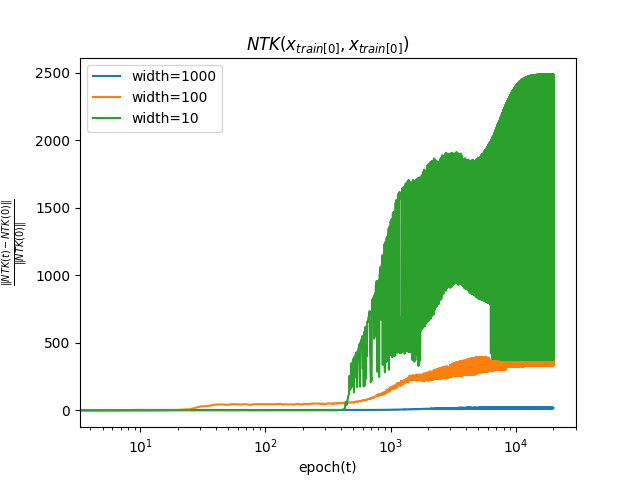
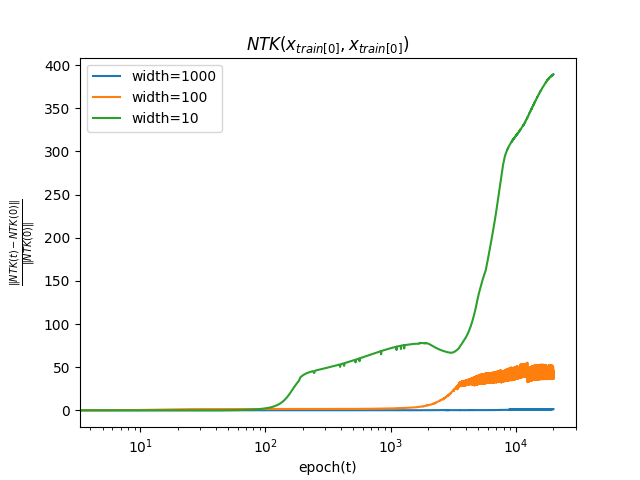
学習中にNTKが初期値からどの程度変化するか, 以下の式を用いて測る.
∣∣K(x0,x0;θ(0))∣∣2∣∣K(x0,x0;θ(t))−K(x0,x0;θ(0))∣∣2
簡単のためNTKの引数はx0同士としている.
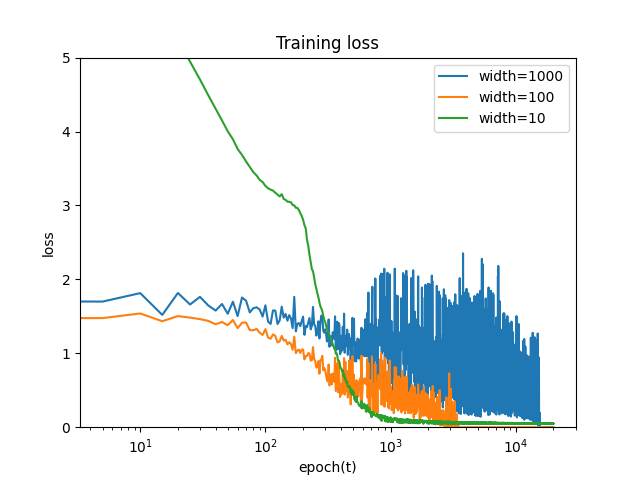
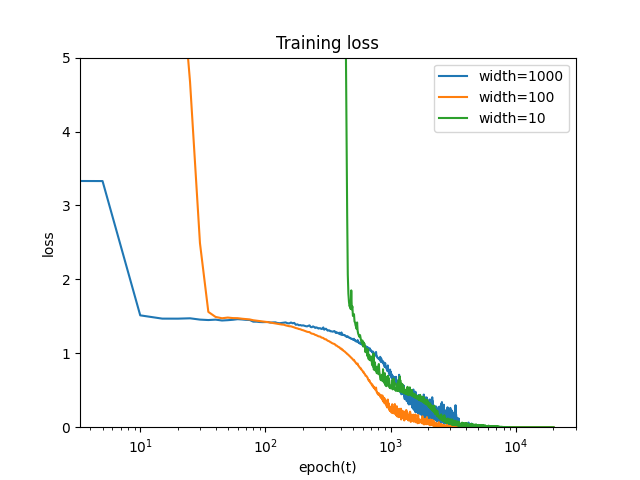
損失L(θ)を測る.
結果
バッチ数によらず, パラメータの初期値からの変化は幅が大きいほど小さいことがわかる. これは, 無限幅において, 学習中に線形モデルで近似できることと整合性がある.
NTKについても, 幅が大きいほど初期値からの変化は小さいことがわかる. これは, 無限幅において, NTKが学習中に変化しないことと整合性がある.
あとがき
深層学習理論の研究は, 実験的な事実から得た謎を理論で暴いていく流れや極限における挙動を見るといった点が物理の作法に近く, 複雑なシステムを解析していく感じで面白いです.
なお, 今回紹介した内容は, Full Batchを用いることや, θ(t)がGradient Flowに従うこと, Fully-Connectedなシンプルなモデルを仮定しており, 現実と離れた設定でした.
今後は仮定を緩めた研究や, 理論研究から応用に活かす設定についてサーベイ, 研究していきたいです.
Ref.