大規模言語モデルのコーパス構築において, テキストデータの重複除去は, 性能の向上やプライバシーリスクの低減に重要な処理と考えられています. そのため, 大規模言語モデルのコーパス構築のフローにDe-duplicationのステップが含まれていることが多いです (以下の図参照).
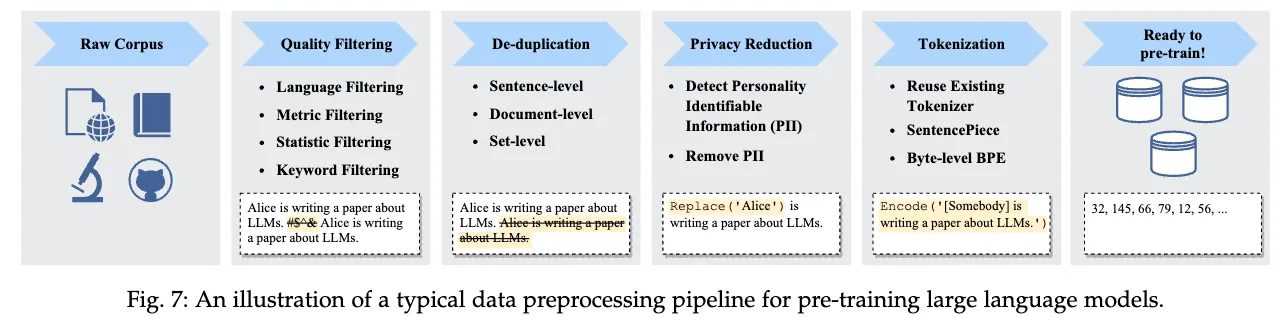
最近の大規模言語モデルのコーパスのサイズは数百GBから数TBにも及ぶため, 重複除去は計算コストが高い処理となります. そこで, 効率的な重複除去手法としてMinHashがよく用いられています. MinHashはテキスト対同士の類似度(Jaccard係数)を効率的に推定する確率的手法です.
本稿では, MinHashの基本的なアイデアと方法, 比較回数の削減方法について説明します.
Table of contents
Open Table of contents
テキスト対の重複の定義
コーパスに含まれるテキストの重複除去を行う上で, 重複をどのように定義するかが重要です. 最も単純な方法は, テキストの完全一致を重複とみなす方法です. しかし, 実際のテキストデータには, 同じ内容であっても, 表現が異なる場合が多く, 完全一致だけでは不十分な場合があります. そのため, テキストの類似度を計算し, 一定の閾値以上の類似度を持つテキストを重複とみなす方法が用いられます.
テキストの類似度の計算方法には, Jaccard係数や編集距離, コサイン類似度などが考えられますが, 今回取り上げるMinHashは, Jaccard係数に基づいた類似度計算手法であるため, ここではJaccard係数について説明します.
Jaccard係数
Jaccard係数は, 2つの集合の類似度を測る指標の1つで, 以下の式で定義されます.
Jaccard係数の良い性質として, 以下が挙げられます.
- , ただし, 0の時は の積集合が空, 1の時は,
つまり, 集合同士の要素が完全に一致する場合, Jaccard係数は1になります. 逆に, 2つの集合の要素が全く一致しない場合, Jaccard係数は0になります.
Jaccard係数をテキスト対の類似度計算に用いる場合は, テキストを集合に変換してから計算します. テキストを集合に変換する方法としては, 例えば, 文字列をn-gramに分割する方法(e.g. “I have a pen” -> {“I hav”, “have a”, “ve a ”, “e a p”, ” a pe”, “a pen”})や, 単語に分割する方法(e.g. “I have a pen” -> {“I”, “have”, “a”, “pen”})があります.
例として, “I have a pen”と“I have an apple”のJaccard係数を計算してみましょう. 今回はテキストを単語に分割して集合に変換します.
A = {”I”, “have”, “a”, “pen”}, B = {”I”, “have”, ”an”, ”apple”}
この時のJaccard係数は,
となります.
Jaccard係数の計算量
Jaccard係数は, Pythonで以下のように実装できます.
def jaccard_similarity(A: set, B: set) -> float:
intersection = len(A & B)
union = len(A | B)
return intersection / unionCPythonのdocument を見ると, intersectionの平均時間計算量は, 最悪時間計算量は であり, unionの平均時間計算量, 最悪時間計算量はどちらも です. よって, Jaccard係数の平均時間計算量は となり, テキストの長さに比例します. これは, テキストが長い場合に計算コストが高くなるため, 大規模なコーパスの重複除去などで大量にJaccard係数を計算する場合, 非常に時間がかかることになります.
MinHashは, Jaccard係数を効率的に推定する確率的手法であり, この問題を解決します.
MinHash
MinHashは, 集合のJaccard係数を効率的に推定する確率的手法です. MinHashのアルゴリズムは以下の通りです.
- 集合の各要素をハッシュ関数でハッシュ値に変換する.
- 集合のハッシュ値のうち, 最小値(minhash)を取得する.
- この時, が成り立つ.
なぜ のminhashが一致する確率がJaccard係数と等しいか考えてみます.
とします. この時, です.
ここで, ハッシュ関数を用いて各要素のハッシュ値を計算します. です. この時, ハッシュ値は の要素分だけ現れます.
よって, のハッシュ値 が で最小値となる確率は です.
また, となるのは, の要素のうち, の要素が最小値となる時に限ります. この確率は, です.
よって, が成り立ちます.
以上から, ある集合のminhashが一致する確率は, Jaccard係数と等しいことがわかります. この結果から, 各集合のminhashを計算しておき, それらを比較することで, Jaccard係数を推定することができます.
ただ, 一つのminhash対のみでは確率値を推定することができないため, 複数のハッシュ関数を用いてminhashが一致する割合を計算し, それをJaccard係数の推定値とします. すなわち, 個のハッシュ関数を用いて, とします. の値が大きいほど, 推定が正確になります.
MinHashの計算量
あらかじめ個のminhashが計算されている場合, 2つの集合のJaccard係数を計算する時間計算量は です.
ただし, minhashの計算自体()には, かかります. そのため, 一回の類似度計算をするためだけにminhashを使うのは効率的ではありません.
逆に, テキストが大量にあって, それらとの類似度を計算するクエリがある場合, のminhashを計算しておけば, クエリとの類似度を計算する時間計算量は です. クエリ数が多い場合は, のminhashの前計算が無視できるため, MinHashを使うことで高速に類似度を計算することができます. 大規模コーパスの重複除去ではテキスト全対の類似度を計算する必要があるため, MinHashは非常に有用となります.
minhashの比較回数を減らす方法
MinHashでは, 個のminhashの比較を行うことで, Jaccard係数を推定します. しかし, 個のminhashを比較するためには, 回の比較が必要となります. Jaccard係数の推定を正確に行うためには, が大きい必要があるため, 比較回数が多くなります. 正確性を犠牲として比較回数を減らすために, minhashをバケットに分ける方法が用いられます. 以下に, バケットに分ける方法について説明します.
minhashの数 として, 個のminhashを, 個のバケットに分けます. 一つのバケットには, 個のminhashが入ります. さらに, バケットのminhashを連結します.
そして, 2つの集合のminhashをバケットに分けた後, それぞれのバケットが一致するかを比較します. これにより比較回数は回になります.
この時, 集合 が の時, 個のバケットが一つ以上一致する確率は以下となります.
導出: 各ハッシュがs個連続して一致する確率は . よって, バケットが一致しない確率は . 個のバケット全てが一致しない確率は よって, 個のバケットのいずれか一つ以上が一致する確率は となる. ■
このように, バケットという大まかな単位で比較し, 一つ以上のバケットが一致したら重複とみなすことで, 比較回数を減らすことができます. ただし, 見逃しをする可能性(false-positive)や, 誤って一致と判定してしまう可能性(false-negative)があります. バケットのサイズ, バケットの数を調整することで, 計算量と正確性のトレードオフを調整することができます.
以下は, FineWeb というコーパスにおいて用いられたMinHashのパラメータの例です. 類似度が大きいほどバケットが一致する確率が高くなることがわかります.
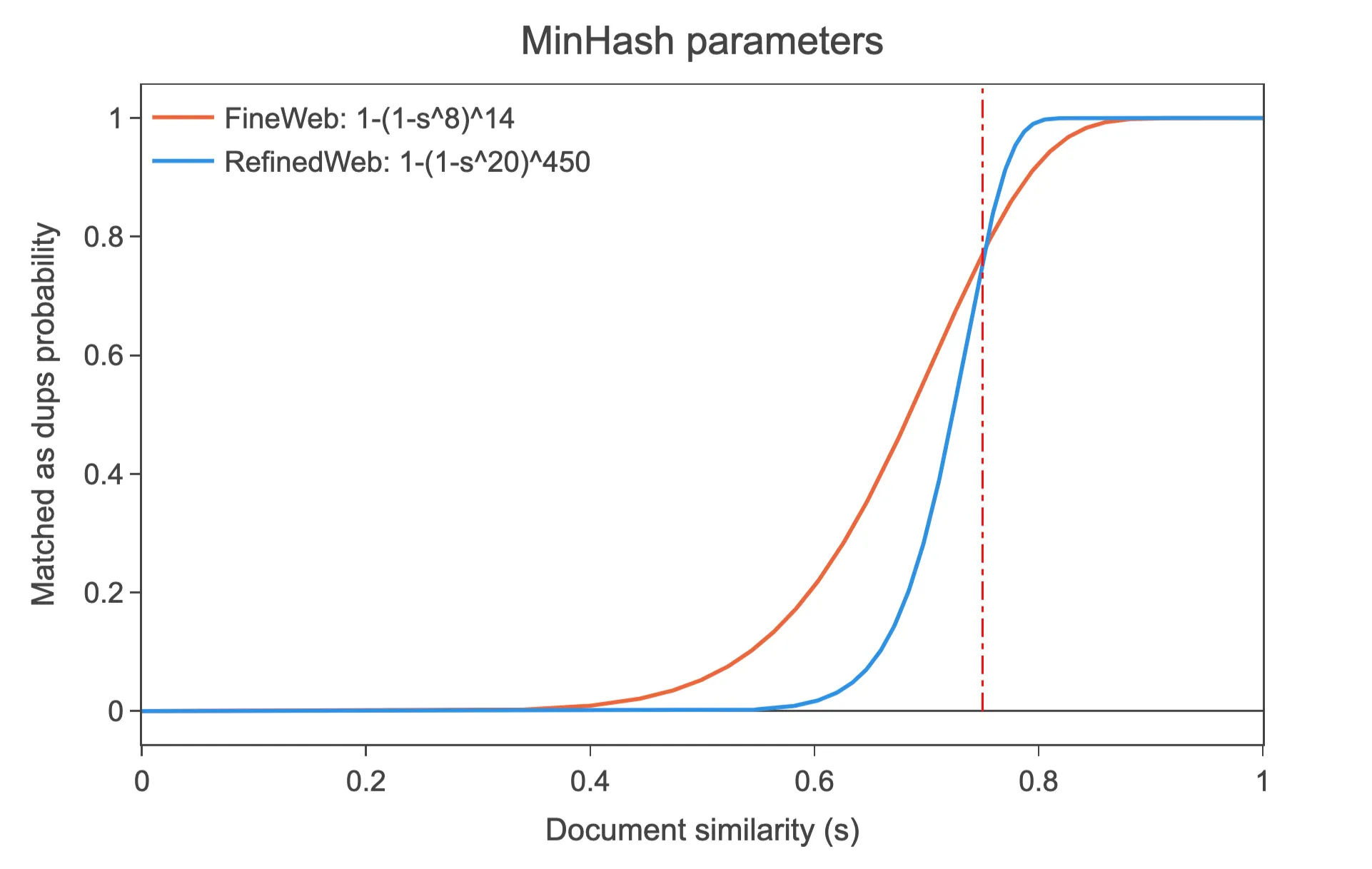
このように 個のminhashをバケットに分割することで, 比較回数を減らすことができます.
まとめと感想
MinHashは, Jaccard係数の計算をminhashの比較で推定できるという面白いアイデアで, アルゴリズム自体も非常にシンプルであることがわかりました.
MinHashについて調べてみると, 約十年ほど前に, 岡野原さんや秋葉さんがMinHashに関する記事やスライドをuploadされており, 長い間使われている手法であることがわかりました. 今再び大きな注目を浴びているのは面白いですね.
また, 大規模言語モデルの開発においては, 事前学習, ファインチューニングの部分に目が行きがちですが, コーパス構築の部分は, 大規模データを扱うために, 大量のCPUコアを用いた並行処理やMinHashやクラスタリングなどの古典的なアルゴリズムが用いられており, コンピュータサイエンスの知見が広く活かせる面白い分野だと感じました.
参考文献
こちらはMinHashの元論文です.
- Leskovec et al., Mining of Massive Datasets - Chapter 3 Finding Similar Items
- Lee et al., Deduplicating Training Data Makes Language Models Better
- Kandpal et al., Deduplicating Training Data Mitigates Privacy Risks in Language Models
- FineWeb: decanting the web for the finest text data at scale
大規模コーパス構築の知見が詰まったHuggingFaceチームによるブログです. De-duplicationの議論がたくさん述べられています.