本稿では, LLM勉強会のマルチモーダルWGの活動でSilviaさんと共同開発している llm-jp-eval-mmという, 視覚言語モデルの日本語性能を評価するツールを紹介します.
Table of contents
Open Table of contents
llm-jp-eval-mm
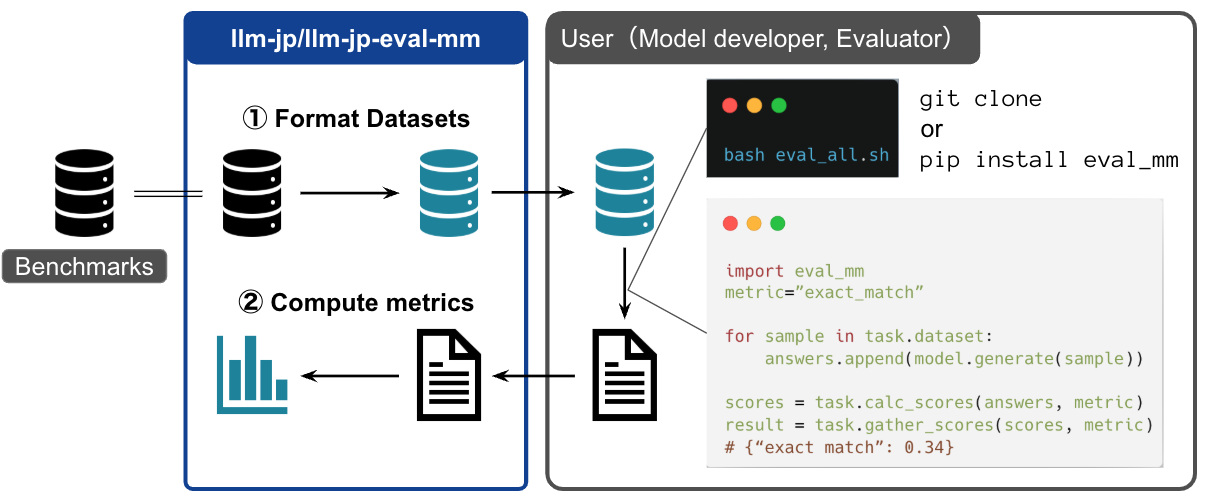
近年, テキストと画像の両方を扱える視覚言語モデルの開発が, 多くの企業や研究機関で活発に進められています. しかし, 日本語のベンチマーク環境は英語に比べて整備が遅れており, 適切な評価を行うのが困難な状況にありました.
そこで, 既存の日本語ベンチマークタスクを活用し, 共通の基盤でモデル評価を行えるようにするために開発されたのが llm-jp-eval-mm です. 本ツールは, 既存の評価ツール(例:lmms-eval)に比べて軽量に設計されており, モデルやベンチマークタスクの追加が容易になっています.
利用可能なタスク
現時点で, 以下のタスクが利用できるようなっています.
日本語タスク
英語タスク
利用例
インストール
本ツールは, モダンな Python パッケージマネージャー uv を利用しており, 以下のコマンドで環境を整えることができます.
uv sync評価
例えば, llava-hf/llava-1.5-7b-hf というモデルを japanese-heron-bench タスクで評価する場合, 以下の手順で実行します.
- 必要な依存関係をインストール
uv sync --group normal- 評価の実行
以下のコマンドで, モデル名・タスク名・評価メトリクスなどを指定します. ここでは llm_as_a_judge による評価を行うため, 評価モデルとして OpenAI のモデルを指定しています (現在は Azure OpenAI API のみに対応).
uv run --group normal python examples/sample.py \
--model_id llava-hf/llava-1.5-7b-hf \
--task_id japanese-heron-bench \
--result_dir test \
--metrics "llm_as_a_judge_heron_bench" \
--judge_model "gpt-4o-2024-05-13" \
--overwrite特徴・工夫点
uvのdependency groupsの活用
視覚言語モデルごとに依存するライブラリが異なるため, 依存関係の衝突が発生しやすい問題があります.
本ツールでは uv の dependency groups を利用し
uv run —group <group name> pythonのようにグループ名を指定することで, 依存ライブラリを適切に管理できます.
軽量な設計
視覚言語モデルの評価は, 主に以下の3つのステップに分かれます.
- 評価データセットの準備(
Taskクラス) - モデルの出力生成(
VLMクラス) - 評価スコア算出(
Scorerクラス)
ステップとクラスを対応付けた設計により, コードの再利用性やテストのしやすさが向上しています.
リーダーボード
以下のWebサイトにて, llm-jp-eval-mmを用いたリーダーボードを公開しています.
https://llm-jp.github.io/llm-jp-eval-mm
(WebサイトはJMMMUのサイトを参考にさせていただきました. ありがとうございます.)
おわりに
本稿では, 視覚言語モデルの日本語性能を評価するツール llm-jp-eval-mm を紹介しました.
ご質問や, 新たなタスク・モデルの追加に関するご要望は, GitHub の Issue や Pull Request でお待ちしております.
また, NLP2025 in 長崎 (2025年3月) では Silvia さんが本ツールについて発表予定です. ぜひお越しください!